
llm-cost-guard
ストックにはログインが必要です
Stop runaway LLM API spend before it happens
Artificial Intelligence
Developer Tools
GitHub
Open Source
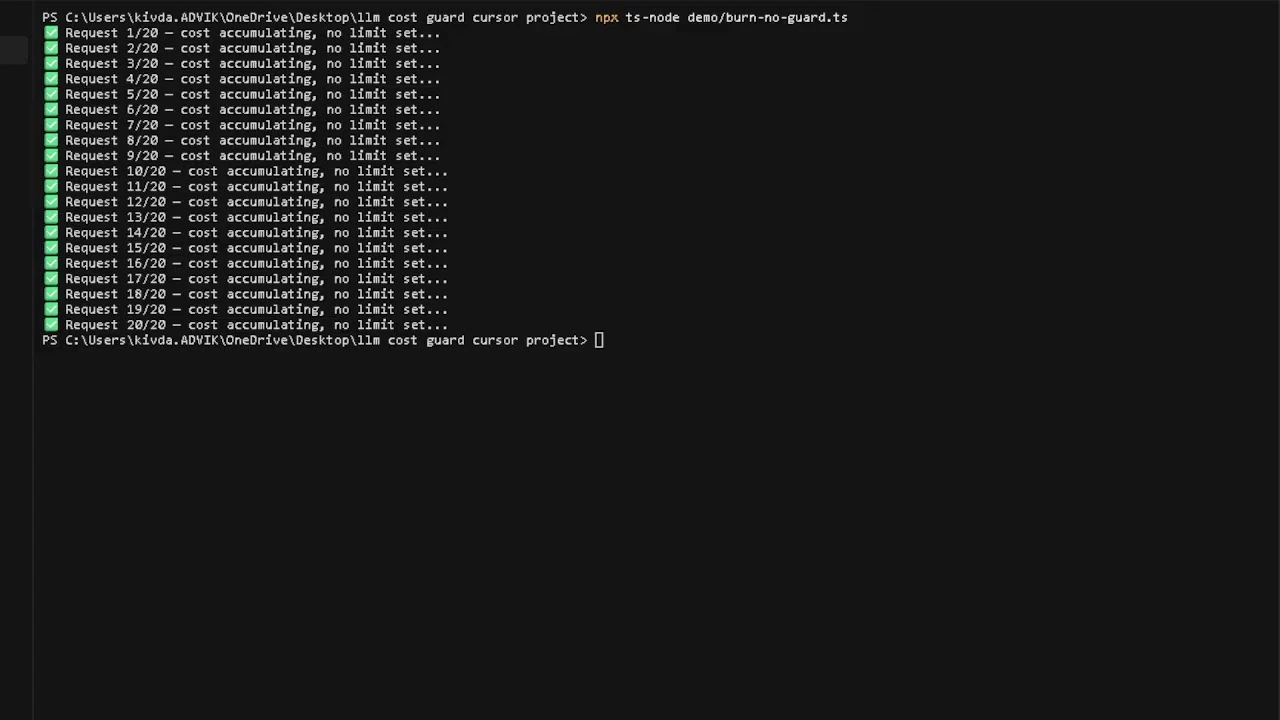
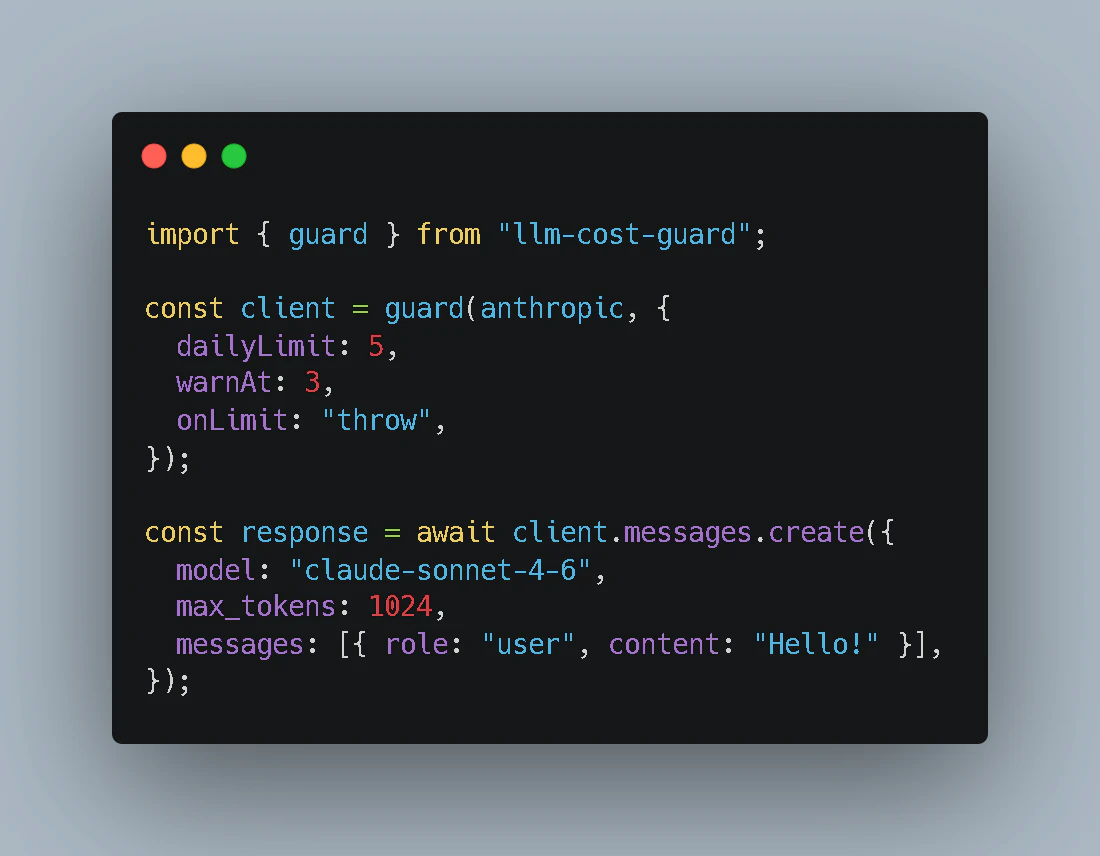
Wrap your Anthropic, OpenAI, or Gemini client with guard() — it tracks token spend on every request and throws a hard stop before you breach your budget. Unlike billing alerts (delayed, non-blocking), llm-cost-guard sits in your code and kills the request before money is spent. Supports per-user limits, Slack/Discord webhooks, pre-flight cost estimation, Redis storage, and full TypeScript types.
投票数: 1